

Session 6️⃣
Manufacturing Data Generation and Inspection Methods
세션 6. AI 기반 제조데이터 생성 및 검사기법
국립창원대학교 권오설 교수
To train a highly accurate classification AI model, it is essential to have a balanced ratio of normal and abnormal data in the training set. However, in industries like manufacturing and machinery, where defects can significantly impact productivity, collecting sufficient abnormal data during the actual production process is often a challenge.
So, what can be done? Should we simply wait until enough abnormal data accumulates?
Professor Oh-Seol Kwon from Changwon National University addressed this issue by utilizing generative AI models to quickly generate large amounts of data. This approach allows the collection of data under specific conditions in a much shorter time frame.
분류 정확도가 높은 AI 모델을 훈련하기 위해서는 훈련 데이터에 정상과 비정상의 데이터 비율이 균형 있게 이루어져야 합니다. 그러나 특히 제조업과 기계 산업과 같이 불량 발생이 생산성에 영향을 미치는 분야의 경우, 비정상 데이터를 실제 공정 과정에서 수집하기 쉽지 않은 것이 현실입니다.
그러면 어떻게 해야 할까요? 마냥 충분한 비정상 데이터가 모일 때까지 기다려야 할까요?
국립창원대학교의 권오설 교수님은 짧은 시간 내에 다양한 데이터를 최대한 많이 확보하기 위해서 생성형 AI 모델을 활용하여 사용자가 원하는 조건에 맞는 데이터를 확보하고자 하였습니다.
Practical Application Cases 🔧
실제 적용 사례
💡 Generative AI-Based Defect Detection System: Precision Automotive Parts Manufacturer
💡 생성형 AI 기반 불량 검출 시스템 : 자동차 정밀부품 제조업체
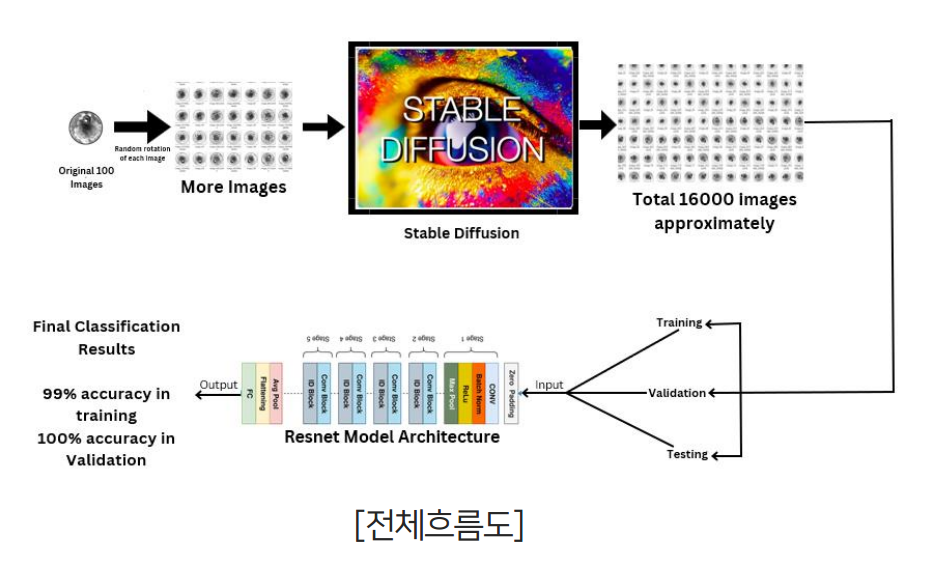
In the case of precision components, even a minor scratch can lead to machine malfunctions, making accurate quality inspection crucial. However, the current reality is that most inspections still rely on the human eye. To address this, Professor Oh-Seol Kwon introduced Computer Vision technology to ensure more precise quality checks.
Initially, the team chose well-known generative models, such as GAN and Stable Diffusion, to create data for training defect detection models. However, with GAN, there was a challenge—generated data often resulted in altered product shapes, which led to inaccuracies. To overcome this, they opted for Stable Diffusion, generating both normal and defective product data to improve the model's training process.

정밀 부품의 경우, 미세한 긁힘만으로도 기계에 오작동을 일으킬 수 있는 아주 섬세한 부품이기 때문에 정확하게 품질을 검사하는 것이 중요하지만 현재는 작업자의 육안검사에 의존하고 있는 것이 현실입니다. 권오설 교수님은 이를 대체하여 더욱 정확한 품질 검사를 할 수 있도록 Computer Vision 기술을 도입하였습니다.
우선 생성형 모델로 가장 유명한 GAN과 Stable Diffusion을 선택해 데이터를 생성하여 불량 검출 모델의 훈련 데이터로 활용하고자 하였습니다. 그러나 GAN의 경우 제품의 모양 자체가 변형된 데이터를 생성하는 문제가 있어 Stable Diffusion으로 양품과 불량품 데이터를 생성하여 활용하였다고 합니다.
GAN (Generative Adversarial Network)란?
GAN(생성적 적대 신경망)은 2014년 Ian Goodfellow가 개발한 생성형 AI 모델로, 두 개의 신경망 (Generator, Discriminator) 이 경쟁하며 점점 더 정교한 데이터를 생성하는 방식
구성 요소
Generator (생성자): 실제 데이터처럼 보이는 가짜 데이터를 생성Discriminator (판별자): 생성된 데이터가 실제인지 가짜인지 판별
작동 방식
1. Generator가 가짜 데이터를 생성
2. Discriminator가 진짜 데이터와 비교하여 판별
3. Discriminator가 속지 않도록 Generator가 더 정교한 데이터를 생성
4. 이 과정이 반복되며, 점점 실제와 구분하기 어려운 데이터를 생성
한계점
- 생성된 이미지가 불안정하거나 변형될 가능성이 있음
- 훈련 과정에서 모드 붕괴(Mode Collapse) 문제가 발생할 수 있음 (같은 패턴의 데이터만 생성)
- 고해상도 이미지 생성에는 한계가 있음
Stable Diffusion이란?
Stable Diffusion(안정적 확산 모델)은 2022년 Stability AI에서 개발한 텍스트-이미지 변환 AI 모델로, 확산 모델(Diffusion Model)을 기반으로 동작한다. GAN과 달리 노이즈를 점진적으로 제거하면서 이미지를 생성하는 방식이다.
작동 방식
- 노이즈 추가: 기존 이미지에 랜덤 노이즈를 점진적으로 추가
- 역방향 과정: 노이즈 제거 과정을 거쳐 점진적으로 고해상도 이미지를 생성
- 텍스트 프롬프트 활용: 텍스트 입력을 기반으로 원하는 스타일과 형태의 이미지 생성
장점
- 높은 해상도의 정밀한 이미지 생성 가능
- 특정 조건(텍스트 프롬프트)으로 원하는 데이터 생성 가능
- GAN보다 더 현실적인 이미지 생성
한계점
학습 과정이 상대적으로 오래 걸리며, 노이즈 제거 과정에서 원하는 결과를 얻기까지 반복적인 프롬프트 수정이 필요